Call : +1 (877)-71-ITUSA
I
Email: info@cogentuniversity.com
Follow:





These days, business is done in real time and digitally. It is imperative to have appropriate real-time data processing to support users' constant expectations for more dynamic and spontaneous experiences. By 2026, the worldwide real-time data analytics market is expected to have grown to $27.7 billion at a CAGR of 20.4%.
In many organizations, data platforms began as batch ETL pipelines that operated hourly or nightly schedules. This approach is effective until business needs contact for immediate action, such as when fraud spikes, unusual activity, or personalization changes occur in a matter of minutes or seconds.
Many early adopters used Kafka + Flink, or Kafka Streams, to create streaming pipelines, writing Java/Scala/Go code, managing state, windowing, and other features to fill that gap. However, those systems required highly skilled experts. The missing component is a SQL abstraction that allows analysts and product teams to have control and visibility without having to manually code each transformation. Two of the most popular methods for bringing SQL to streaming are Flink SQL and ksqlDB.
In this article, we will learn about the major stream processing frameworks, their distinctive features, advantages, and trade-offs.
Apache Flink's wide range of features makes it an excellent choice for creating and executing several applications. Stream and batch processing, event-time processing semantics, and advanced state management are some of the features of Flink.
It is also possible to deploy Flink as a standalone cluster on bare-metal hardware and different resource providers like YARN and Kubernetes. Flink has been shown to provide high throughput and low latency, and expand to thousands of cores and terabytes of application information.
Recently, Apache Flink has increased in popularity as a potent distributed processing solution for stateful computations. The following are just a few of the numerous benefits of using Apache Flink:
Across a variety of sectors, Apache Flink facilitates real-time data processing. Applications that are scalable and low-latency can rapidly convert streaming data into actionable insight, ranging from fraud detection and predictive maintenance to consumer personalization.
Apache Flink effectively handles continuous event streams from many sources and initiates real-time operations, including calculations, state changes, and external workflows. Low latency and high throughput are made possible by its local state management and in-memory data access, which makes it perfect for use cases like process automation, fraud detection, and anomaly detection.
Flink supports real-time streaming pipelines that enable continuous data transfer across storage systems. While managing unlimited data flows, it ensures low latency and excellent scalability. Continuous ETL, real-time log aggregation, and live search index generation are common implementations that help businesses maintain always-fresh, analytics-ready data across distributed environments.
Flink can examine millions of financial transactions per second using Complex Event Processing (CEP) to spot unusual patterns of activity, such as several high-value transfers in quick succession. Instant alerts or automatic blocking are made possible by this real-time analysis, which greatly improves fraud prevention and compliance in banking and fintech settings.
A constantly updated 360° customer view is produced by Flink, which processes user interactions, clickstreams, transactions, and browsing data in real time. This makes it easier to use behavioral analytics, product suggestions, and dynamic pricing. Flink makes data-driven personalization and feature engineering possible for contemporary e-commerce and marketing applications by integrating with machine learning models.
To identify irregularities and anticipate equipment problems before they happen, Flink gathers and examines high-velocity sensor data from industrial IoT devices. Through data-driven predictive insights, a real-time analytics pipeline improves operational efficiency in the manufacturing, shipping, and energy sectors, facilitates proactive maintenance scheduling, and decreases downtime.
Teams that use ksqlDB/Kafka Streams, on the other hand, need less time to manage their solutions as well as less expertise to get started. Through the use of Kafka Connect, ksqlDB, and Kafka Streams, it can be easily integrated with both Kafka and external systems. In addition to being simple to use, production stream processing systems that require huge scale and state also use ksqlDB.
Stream processing's availability as a fully managed service, the administrative expense of utilizing a collection of files as opposed to a separate framework, and the availability of local support are all important considerations.
The following are some of the main advantages of ksqlDB and explain why stream processing uses it so frequently.
With ksqlDB, businesses can create event-driven, real-time applications with a syntax similar to that of SQL. This reliable streaming database, which is based on Apache Kafka, is ideal for applications that need to handle and analyze data instantly.
Real-time transaction stream analysis by financial institutions allows them to identify suspicious trends such as geographical irregularities or several significant transactions in just a short period of time. This stream can be continually searched by ksqlDB, which can raise alarms for possible fraud before it escalates.
Financial organizations can switch from batch systems to a real-time, event-streaming architecture for their key banking operations by using ksqlDB. Data from mainframes is transferred to more flexible systems, allowing for immediate client notifications regarding account changes.
Real-time aggregation of incoming sales data streams allows businesses to quickly gather information about consumer behavior, product performance, and market trends. This facilitates real-time analytics and business intelligence.
Businesses can predict equipment breakdowns by examining an ongoing stream of sensor data from IoT devices. This data may be queried using ksqlDB to search for trends that might indicate a possible issue. Real-time network performance metrics streams can be analyzed by telecom corporations using ksqlDB. This enables the prompt detection and fixing of problems that might affect the quality of services.
Real-time analysis of customer complaint data streams allows customer support staff to see patterns and frequent problems. This enhances overall service quality and makes it possible to respond to consumer issues more quickly.
For stream processing, a comparison of Apache Flink and ksqlDB reveals their varied strategies and applicability for various use cases.

A distributed streaming dataflow engine with a general-purpose architecture, Flink is intended for processing data at high throughput and low latency. It has a comprehensive collection of Java, Scala, and Python APIs and supports both batch and stream processing.
A distributed runtime that autonomously monitors resource allocation, fault tolerance, and state serves as the heart of the Flink architecture.
ksqlDB offers a SQL-like interface for stream processing within the Kafka environment and is based on Apache Kafka and Kafka Streams.
By abstracting away the complexity of Kafka Streams and enabling users to create continuous enquiries using well-known SQL syntax, it improves stream processing.
Flink is a strong option for real-time applications because of its Performance Metrics, which demonstrate its capacity to manage high-throughput data processing with little interruption.
When it comes to maximizing resource allocation and utilization, Flink's Resource Management is exceptional, ensuring that computing resources are distributed among tasks in an effective manner.
The performance metrics of ksqlDB highlight how effective it is at stream processing tasks, although it may not be able to handle complicated analytical workloads.
The emphasis on simplicity and use in ksqlDB's Resource Management may result in some drawbacks when managing resource-intensive tasks.
Apache Flink enables developers to create complicated stream processing systems with fine-grained control by providing more flexibility through support for different programming languages (Java, Scala, and Python).
ksqIDB simplifies common stream processing activities like filtering, aggregation, and joining, and places an emphasis on ease of use with its SQL-like language, making it accessible to users used to traditional database searches.
Apache Flink is renowned for its scalability, providing a solid foundation for real-time processing of large data streams. Flink facilitates efficient horizontal scalability according to fluctuating workload needs with its distributed streaming dataflow engine.
Through this approach, users may dynamically increase the scope of their stream processing capabilities, ensuring maximum performance and resource utilization across a variety of use scenarios.
The scalability of ksqlDB can be seen by its effective real-time data processing and transformations across streaming data sources. By using the capabilities of Apache Kafka and Kafka Streams, ksqlDB is beneficial for managing workloads requiring low latency and high throughput.
To meet the changing demands of contemporary companies looking for flexible stream processing solutions, ksqlDB optimizes data processing and transformation activities in flight.
Flink provides a range of online courses designed for students of all ability levels. Fundamental ideas, practical applications, and best practices for using Flink vs. Ksqldb in stream processing projects are all covered in these courses.
For developers who want to learn more about the Flink platform, the comprehensive documentation produced by the community is a great resource. To accelerate the learning process, it includes use cases, tutorials, and troubleshooting instructions.
Using SQL-like queries, ksqlDB provides interactive lessons that guide users through a variety of stream processing scenarios. A large number of articles, frequently asked questions, and use case examples can be found in the ksqlDB knowledge collection to help users manage common challenges and improve their stream processing operations.
For individuals planning to expand their knowledge, attending ksqlDB training seminars offers an intensive educational experience. Advanced subjects, including performance tuning methods and optimization approaches, are covered in these sessions.
Stability in operations is essential. Here are some recommendations, runbooks, and patterns for backfills, exactly-once semantics, GDPR deletes, observability, and schema evolution.
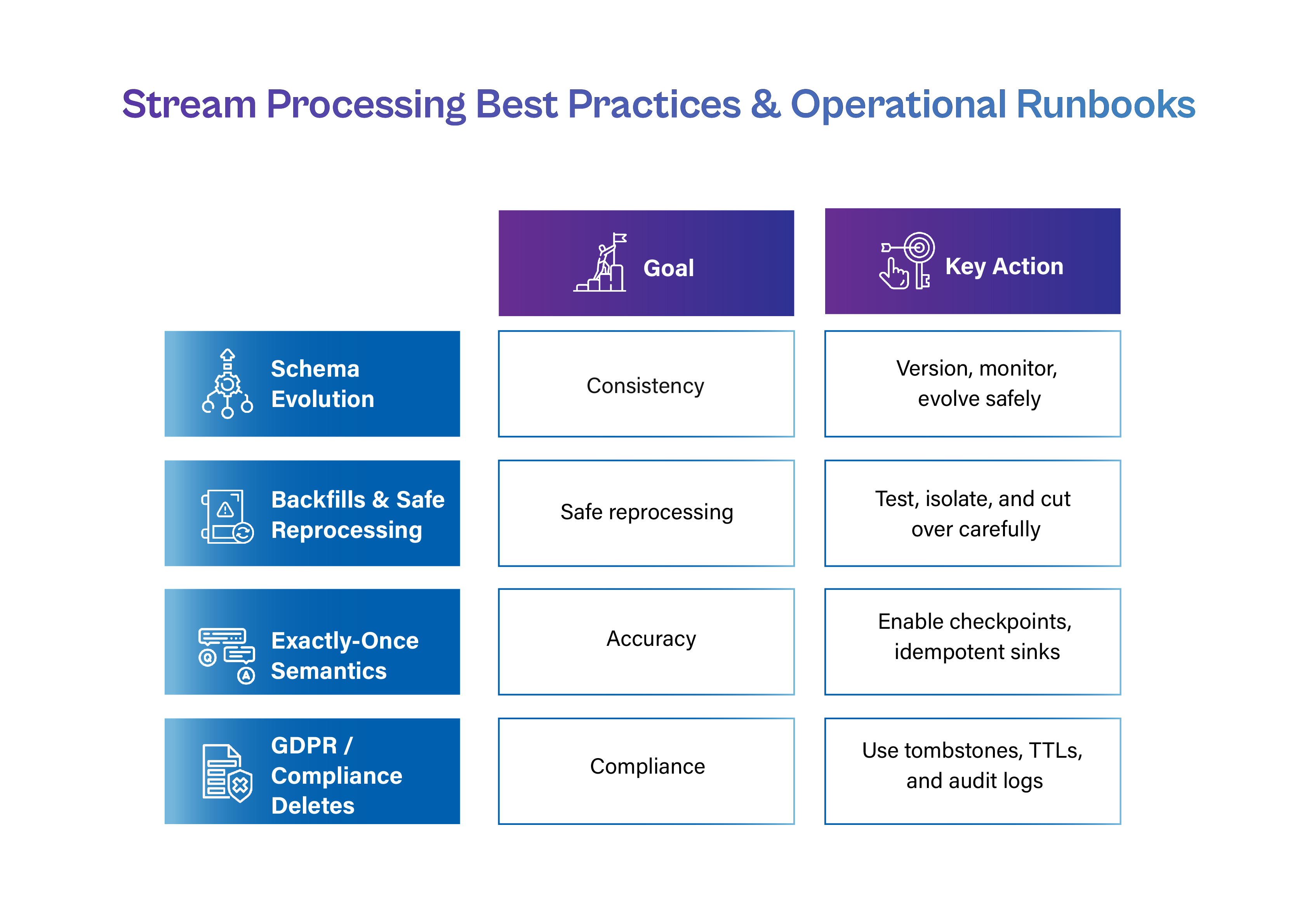
Sometimes you will need to reprocess previous information (e.g., logic correction, bug fix).
To ensure correctness
Sometimes, current systems need to allow data expiry or deletion (such as the "right to be forgotten").
For real-time stream processing, Confluent uses SQL, mostly through Apache Flink SQL and ksqlDB in Confluent Cloud. These tools enable stream transformations, aggregations, and enrichments by letting users engage with Kafka topics and other data sources using well-known SQL syntax.
The following examples show typical use cases for Confluent SQL:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
amount DOUBLE,
order_timestamp TIMESTAMP(3)
) WITH (
'kafka_topic' = 'orders_topic',
'value.format' = 'json',
'properties.bootstrap.servers' = 'pkc-xxxx.us-central1.gcp.confluent.cloud:9092',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username=\"<API_KEY>\" password=\"<API_SECRET>\";',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'PLAIN'
);
In this example, a ksqlDB/Flink SQL orders table is created and mapped to a Kafka topic called orders_topic, whose entries are represented in JSON. It also contains the Confluent Cloud connection characteristics that are required.
Code
SELECT order_id, customer_id, amount
FROM orders
WHERE amount > 100;
This query filters for orders with a quantity larger than 100 by selecting order_id, customer_id, and amount from the orders stream.
Code
SELECT
TUMBLE_START(order_timestamp, INTERVAL '1' MINUTE) AS window_start,
customer_id,
SUM(amount) AS total_amount_in_window
FROM orders
GROUP BY TUMBLE(order_timestamp, INTERVAL '1' MINUTE), customer_id;
It's becoming difficult to distinguish between data engineering and AI engineering. With real-time pipelines becoming the intellectual property of contemporary businesses, SQL-on-streaming platforms such as Flink SQL, ksqlDB, and RisingWave are taking on a new function that involves more than simply data movement; it involves intelligence activation.
Traditionally, streaming systems were designed to handle numerical data, including windows, counts, averages, and joins. They are now being expected to deal with context.
Recommendation engines, real-time decision engines, and large language models (LLMs) are all powered by that context.
In addition to identifying user clicks, the next generation of data pipelines will also provide semantic meaning to those clicks ("why," "from where," and "what's next?"). and enter data into an AI model, which generates a personalized message, sends an alarm, or displays an offer in milliseconds.
Because of this convergence, current pipelines need to change to support:
Today, most businesses keep an assortment of streaming tasks, ETL scripts, and APIs that supply their machine learning systems. The logic for scheduling, monitoring, and scaling varies from component to component.
The way the future is unified is declarative streaming, which is a single abstraction that resembles SQL and allows developers to specify what needs to happen while the underlying system determines the most effective way to accomplish it immediately.
Early iterations of this can be found in:
Eventually, all streaming SQL has a democratizing potential in addition to a technological one. Declarative AI pipelines with streaming SQL will enable real-time decision-making for anyone, much as the original SQL language made data analysis accessible to millions.
Without writing a single line of Python or Java code, engineers, analysts, and even product managers will be able to define business logic that responds to real-time data. An intelligent, more responsive business is the end result, where choices, insights, and personalization are made as data flows rather than after it settles.
In summary, real-time data systems are now a competitive need rather than only a technological objective. Organizations can bridge the gap between data creation and data action by combining Kafka, Flink, and SQL-based streaming layers like Flink SQL and ksqlDB. Anyone proficient with SQL may now more easily do tasks that formerly needed intricate, code-heavy engineering.
Real-time pipelines have the potential to revolutionize operational intelligence, personalization, and fraud detection, as this article explained. They lay foundations for AI-driven decision-making while providing measurable decreases in risk and latency. These systems are becoming sufficiently robust for use in mission-critical applications because of exactly-once semantics, schema governance, and operational runbooks.
In the future, streaming SQL will act as the link between intelligence and data. It will drive adaptive experiences, predictive analytics, and LLM scoring, all of which are continually improved by real-time feedback loops. Teams that view real-time as the norm rather than an upgrade will be the ones of the future. Early adopters of these designs will not only respond more quickly, but they will also think more quickly, creating organizations where insight and data flow as a single, uninterrupted stream.
Join Cogent University’s hands-on training programs and master Apache Flink, Kafka, and SQL-based streaming frameworks, the backbone of modern enterprise AI.
Explore Courses
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.
Ever wondered how computer programming works, but haven't done anything more complicated on the web than upload a photo to Facebook?
Then you're in the right place.
To someone who's never coded before, the concept of creating a website from scratch -- layout, design, and all -- can seem really intimidating. You might be picturing Harvard students from the movie, The Social Network, sitting at their computers with gigantic headphones on and hammering out code, and think to yourself, 'I could never do that.
'Actually, you can. ad phones on and hammering out code, and think to yourself, 'I could never do that.'







