Call : +1 (877)-71-ITUSA
I
Email: info@cogentuniversity.com
Follow:





Test-Driven Development (TDD) can breathe new life into legacy code by introducing a safety net of automated tests. Building that safety net enables teams to confidently modernize a legacy system without constantly fearing regressions. Legacy code – often defined as “code without tests” – is notoriously hard to change safely. In this post, we outline how to implement TDD in legacy systems step by step, highlighting practical strategies (like characterization tests and incremental refactoring) to gradually improve code quality and support modernization.
TDD is the practice of writing tests before writing or changing code. Developers follow a red-green-refactor cycle: write a failing test for a desired behavior (red), write just enough code to pass the test (green), then refactor the code safely while tests remain green. This ensures each new change is verified by an automated test, making the codebase more reliable over time.
Legacy software typically refers to an outdated codebase (often mission-critical) that is challenging to maintain. A key trait is a lack of automated tests, which makes modifications risky. Michael Feathers famously defined legacy code as “simply code without tests”. Without tests, developers must guess at the code’s behavior, increasing the chance of regressions. In short, TDD thrives on testable, well-designed code, whereas legacy systems often lack the safety nets that tests provide. Modernizing a legacy system means bridging this gap – bringing the benefits of TDD (rapid feedback, safe refactoring, cleaner design) into an old codebase to make it more robust and adaptable.
Legacy code can feel like an insurmountable mountain when trying to apply TDD. In many teams, there’s a belief that “TDD won’t work on our legacy code” – adding tests to an old, tightly-coupled system can seem prohibitively slow or complex. Overcoming this mindset requires understanding the specific challenges that make legacy TDD tricky:

These challenges are significant, but they can be addressed with a strategic approach. Next, we’ll explore how to implement TDD in a legacy codebase despite these obstacles, using careful techniques to create the necessary test scaffolding and gradually modernize the system.
Despite these hurdles, there are proven strategies to gradually introduce TDD into a legacy codebase. Key strategies include writing characterization tests, refactoring for testability, and leveraging TDD for new changes.
When you inherit code with no tests, the first step is often to write characterization tests. A characterization test documents what the code currently does, rather than what it’s supposed to do. In other words, you use these tests to capture the existing behavior (even if it’s buggy or odd) so that any future change can be checked against the original behavior.
To create a characterization test, identify a module or function in the legacy code that you need to change or understand. Write a test with an expected result that might be incorrect (a guess), run it, and observe how the real code behaves. Then adjust the test’s expected value to match the actual output of the code. Repeat this for different inputs until the tests cover the key behaviors of that component. Essentially, you’re “interviewing” the code with tests to learn its behavior and locking that knowledge in via assertions.
The result is a safety net of tests describing the legacy code’s current functionality. These tests will fail if you accidentally change something in that component’s behavior. With a suite of characterization tests in place, you can refactor with confidence – if you introduce a defect, a test will catch it immediately. This gives you the freedom to start improving the code’s structure.
Legacy code often wasn’t written with testability in mind, so it’s full of hardwired dependencies – calls to databases, file systems, singletons, etc. that are difficult to run in a test harness. A crucial strategy is to refactor the code just enough to break these dependencies and create seams where tests can be inserted. Michael Feathers notes that separating dependencies is often the hardest part of working with legacy code, but it’s necessary to enable unit testing.
Focus on small, surgical changes that make the code more test-friendly without altering its behavior. For instance, if a function reads from a file or global object, modify it to accept that data as a parameter; if a class instantiates its own database connection, make it accept a database interface or connection object instead. These tweaks allow you to substitute real dependencies with test doubles (mocks or stubs) when running the code under test. Using mocking frameworks can simulate a database or external service so you can test the business logic in isolation.
Apply the smallest change needed to get the code under test. Each dependency you peel away and cover with a test increases the portion of the system protected by your safety net. Over time, these incremental refactors greatly improve the modularity of the codebase.
Another way to introduce TDD is when adding new features or major changes: use the “sprout method” approach. Instead of injecting new code directly into the tangled legacy logic (where it’s hard to test), you create an extension point in the old code and build the new functionality in isolation using TDD.
Practically, this means doing a minimal refactoring of the legacy code to make it more extensible. For example, you might add a new interface or hook method that the legacy code will call. Initially this hook might call a dummy implementation, but it provides a place to “plug in” new behavior. Once the extension point is in place, implement the new feature in a fresh module or class using TDD – writing tests for the new code from the start and ensuring it works independently. When the new code is ready and well-tested, integrate it by having the legacy code call into it (via the interface or hook you introduced). Then run all tests (including your characterization tests) to verify that the new feature hasn’t broken any existing behavior.
With this approach, even if the surrounding legacy code isn’t well-tested, your new functionality is developed with high quality. You’ve effectively grown (“sprouted”) a new, test-covered piece of code out of the old system.
When using this technique, keep the initial change to the legacy code as small as possible (e.g. one new method or a few lines) and verify nothing breaks after adding the extension point. It’s wise to use any existing manual or automated tests to check the system’s behavior before and after the change. Some teams even set up a temporary golden master test (capturing the current outputs of the system for a given set of inputs) before refactoring, so they can compare results after and ensure equivalence. Once the new TDD-developed code is integrated and working, you can gradually refactor the surrounding legacy code in subsequent iterations.
Whenever you fix a bug or add an enhancement in the legacy system, start by writing a test that exposes the issue or defines the new behavior. Then make the code change and ensure that test passes. This way, the next time someone inadvertently breaks that functionality, the test suite will catch it.
Similarly, before refactoring a messy legacy function, make sure you have tests (perhaps characterization tests) covering its current behavior; then refactor in small steps, running the tests after each change to confirm nothing else broke. Make sure to run the tests on every commit (via continuous integration) so any regression is caught immediately. Over time, developers gain the confidence to add features or refactor without constantly fearing breaks in old functionality.
For a practical roadmap, here is a simplified step-by-step approach to start implementing TDD in a legacy project:
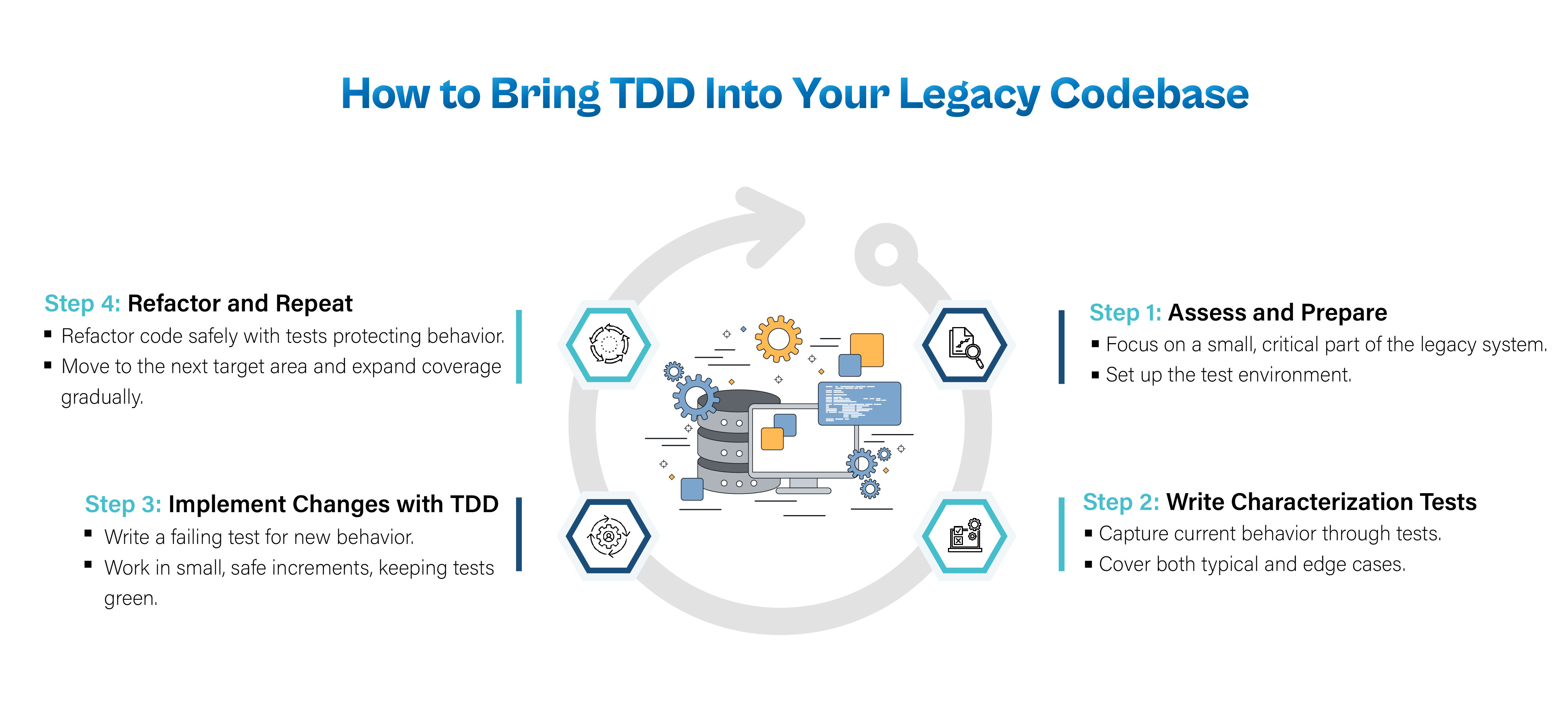
When modernizing a legacy system with TDD, keep these best practices in mind and watch out for common pitfalls:
Changing legacy code without any tests – a tactic often called “edit and pray” – and simply hoping nothing breaks. This is risky and often leads to regressions discovered late (or by end users). Instead, always “cover” the code with at least one test before you modify it (“cover and modify”). Even a basic sanity test is better than nothing – that safety net will catch many side effects and give you confidence to keep improving the code.
Implementing TDD in a legacy system is a journey of gradual improvement, but the payoff is huge: a fragile codebase becomes far more stable and malleable. By introducing tests, you create a safety net that catches regressions and frees you to refactor boldly. Over time, developers gain the confidence to add features or refactor without constantly fearing breaks in old functionality. In essence, TDD lets you modernize in place. Instead of halting everything for a full rewrite, you continuously improve the legacy system while still delivering features to users. Old systems can be updated to modern standards – one test at a time.
Legacy code isn’t going anywhere. The question is: can you improve it without breaking things?
If you’re serious about building reliable systems, Test-Driven Development is non-negotiable. And not the sanitized kind from textbooks, the kind you apply to real, messy, business-critical code.
At Cogent University, we don’t just teach TDD. We make sure you can use it when it counts, inside legacy codebases that power real companies.
Want in? Let’s get to work. Apply Now!.
Q: Should we rewrite the entire legacy application from scratch instead of refactoring and adding tests gradually?
A: In most cases, no. A big-bang rewrite is extremely time-consuming and risky – you may end up recreating old bugs or losing critical business logic. Incremental modernization is safer and more practical. By steadily adding tests and improving the existing code, you can modernize the system piece by piece while continuing to deliver value. (On rare occasions a rewrite is justified, but even then, having a test suite on the old system helps you understand its behavior before replacing it.)
Q: We don’t have time to test everything. Where should we begin?
A: Focus on high-risk, frequently changed areas first. Start by writing tests whenever you touch legacy code; over time, the most critical parts will naturally get covered.
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.
Ever wondered how computer programming works, but haven't done anything more complicated on the web than upload a photo to Facebook?
Then you're in the right place.
To someone who's never coded before, the concept of creating a website from scratch -- layout, design, and all -- can seem really intimidating. You might be picturing Harvard students from the movie, The Social Network, sitting at their computers with gigantic headphones on and hammering out code, and think to yourself, 'I could never do that.
'Actually, you can. ad phones on and hammering out code, and think to yourself, 'I could never do that.'







